Service Maker for C/C++ Developers#
Getting Started with Service Maker C++ APIs#
Before starting on the actual application, we need to create a text file with name ‘CMakeLists.txt’ for building our application later:
cmake_minimum_required(VERSION 3.16)
project(Sample)
find_package(nvds_service_maker REQUIRED PATHS /opt/nvidia/deepstream/deepstream/service-maker/cmake)
add_executable(my-deepstream-app my_deepstream_app.cpp)
target_link_libraries(my-deepstream-app PRIVATE nvds_service_maker)
Now we can create a sample deepstream app (my_deepstream_app.cpp) with a pipeline to perform object detection from a incoming video stream:
#include "pipeline.hpp"
#include <iostream>
using namespace deepstream;
#define CONFIG_FILE_PATH "/opt/nvidia/deepstream/deepstream/samples/configs/deepstream-app/config_infer_primary.yml"
int main(int argc, char *argv[])
{
try {
Pipeline pipeline("sample-pipeline");
pipeline.add("nvurisrcbin", "src", "uri", argv[1])
.add("nvstreammux", "mux", "batch-size", 1, "width", 1280, "height", 720)
.add("nvinferbin", "infer", "config-file-path", CONFIG_FILE_PATH)
.add("nvosdbin", "osd")
.add("nveglglessink", "sink")
.link({"src", "mux"}, {"", "sink_%u"}).link("mux","infer", "osd", "sink");
pipeline.start().wait();
} catch (const std::exception &e) {
std::cerr << e.what() << std::endl;
return -1;
}
return 0;
}
In order to build the application, we should use the CMake to create build environment:
$ mkdir build && cd build && cmake .. && make
Once the build is complete, we can run the application to start the object detection pipeline:
$ ./my-deepstream-app file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_720p.mp4
Currently, despite the pipeline running, we aren’t obtaining object information from the application. To access this data, we need to create a buffer probe that iterates through the metadata generated by the nvinfer plugin.
A sample metadata probe can be implemented as follows:
class ObjectCounter : public BufferProbe::IBatchMetadataObserver
{
public:
ObjectCounter() {}
virtual ~ObjectCounter() {}
virtual probeReturn handleData(BufferProbe& probe, const BatchMetadata& data) {
data.iterate([](const FrameMetadata& frame_data) {
auto vehicle_count = 0;
frame_data.iterate([&](const ObjectMetadata& object_data) {
auto class_id = object_data.classId();
if (class_id == 0) {
vehicle_count++;
}
});
std::cout << "Object Counter: " <<
" Pad Idx = " << frame_data.padIndex() <<
" Frame Number = " << frame_data.frameNum() <<
" Vehicle Count = " << vehicle_count << std::endl;
});
return probeReturn::Probe_Ok;
}
};
By attaching the buffer probe into the inference plugin within the existing pipeline before starting it, we’ll get the vehicle count information from each frame of the video stream:
pipeline.attach("infer", new BufferProbe("counter", new ObjectCounter));
Rebuild the application and run it again, vehicle count will be printed out.
......
Object Counter: Pad Idx = 0 Frame Number = 132 Vehicle Count = 7
Object Counter: Pad Idx = 0 Frame Number = 133 Vehicle Count = 8
Object Counter: Pad Idx = 0 Frame Number = 134 Vehicle Count = 7
Object Counter: Pad Idx = 0 Frame Number = 135 Vehicle Count = 8
Object Counter: Pad Idx = 0 Frame Number = 136 Vehicle Count = 9
Object Counter: Pad Idx = 0 Frame Number = 137 Vehicle Count = 7
Object Counter: Pad Idx = 0 Frame Number = 138 Vehicle Count = 9
Object Counter: Pad Idx = 0 Frame Number = 139 Vehicle Count = 9
Object Counter: Pad Idx = 0 Frame Number = 140 Vehicle Count = 9
Object Counter: Pad Idx = 0 Frame Number = 141 Vehicle Count = 11
.....
Application Developer Fundamentals#
Pipeline#
A pipeline serves as the foundation of Deepstream-based AI streaming applications. Media streams flow through interconnected functional blocks within a pipeline, processed via buffers widths metadata. A pipeline and the elements within it autonomously manage states and data flow, reducing the need for external intervention by application developers.
A functional pipeline requires appropriate elements from Deepstream plugins to be added, configured and linked correctly. This can be seamlessly achieved using Pipeline APIs in a fluent manner:
Pipeline pipeline("sample");
// nvstreammux is the factory name in Deepstream to create a streammuxer Element
// mux is the name of the Element instance
// multiple key value pairs can be appended to configure the added Element
pipeline.add("nvstreammux", "mux", "batch-size", 1, "width", 1280, "height", 720);
For elements that have single static input and output, links can be established in a very straightforward manner:
pipeline.link("mux", "infer", "osd", "sink");
However, if an element supports dynamic or multiple input/output, extra information is required to establish the link:
// link the Element named "src" to the one named "mux"
// given the input of a nvstreammux is dynamic, we must specify the input name "sink_%u" (refer to the plugin documentation)
pipeline.link({"src", "mux"}, {"", "sink_%u"});
Pipeline construction can also be achieved through a declarative YAML configuration file, significantly reducing coding efforts in application development. The above pipeline can be defined as follows in YAML configuration.
deepstream:
nodes:
- type: nvurisrcbin
name: src
- type: nvstreammux
name: mux
properties:
batch-size: 1
width: 1280
height: 720
- type: nvinferbin
name: infer
properties:
config-file-path: /opt/nvidia/deepstream/deepstream/samples/configs/deepstream-app/config_infer_primary.yml
- type: nvosdbin
name: osd
- type: nveglglessink
name: sink
edges:
src: mux
mux: infer
infer: osd
osd: sink
And with the YAML configuration being applied, the application source can be simplified a lot:
#include "pipeline.hpp"
#include <iostream>
using namespace deepstream;
int main(int argc, char *argv[])
{
try {
Pipeline pipeline("my-pipeline", "config.yaml");
pipeline["src"].set("uri", argv[1]);
pipeline.start().wait();
} catch (const std::exception &e) {
std::cerr << e.what() << std::endl;
return -1;
}
return 0;
}
The YAML configuration of a pipeline begins with a “deepstream” keyword, and is composed of two sections:
Node definition list under “nodes”: each item defines an instance to be added to the pipeline, with “type”, “name” and “properties” specified. The “type” field corresponds to the element name defined in DS plugins, such as “nvstreammux”; “name” is a string to identify the instance within the pipeline and must be unique; “properties” field initialize the supported properties for the instance.
Link definition list under “edge”: each item defines one or more connections, where the key specifies the source and the value specifies the target(s). In the case that a source has more than one output, the output name should also be specified, such as “source.vsrc_%u: mux”.
Guideline for Fine-tuning a Pipeline through Configuration File#
The YAML configuration file also offers users a straightforward option to finely tune the pipeline, enabling them to optimize performance effortlessly.
Users can always start with a pipeline design from the blueprint with appropriate nodes and edges, tailored precisely to suit the specific objectives of their projects. Before proceeding, it’s essential to address the following parameters:
batch-size: this is a important property that could affects the performance. It specifies the total number of frames for streammux to create a batch, it must equal to the maximum streams expected to be fed into the pipeline. It is an inherent parameter of “streammux”, while in the case of “nvmultiurisrcbin”, “max-batch-size” should be set instead.
batched-push-timeout: this is another property for “streammux” or “nvmultiurisrcbin”. It determines how long streammux will wait until all the frames are collected, given the batch-size. Change in batched-push-timeout affects the framerates, especially when the input is live source, e.g RTSP.
buffer-pool-size: this property defines the number of buffer pool used by streammux. In scenarios where the processing latency is prolonged to the extent that the buffer pool depletes before a buffer is returned, adjustments to certain properties may be necessary. Nonetheless, it’s imperative to ensure that these adjustments do not surpass a limit of 16.
In the majority of cases, performance degradation stems from hardware bottlenecks, which may arise from the CPU, GPU, or other components. To identify bottlenecks, users can modify the type of potentially problematic nodes to “identity,” effectively disabling them, and then retest the performance iteratively until the actual bottleneck is pinpointed.
Another factor contributing to performance degradation occurs when the pipeline lacks full parallelization, often resulting from irregular overloading of certain nodes. In such instances, inserting a queue before the problematic node can provide a solution.
Additionally, unnecessary scaling can lead to wasteful computation. Therefore, it’s beneficial to carefully consider the processing dimensions for each node. Ensuring that the processing dimension aligns with either the input/output dimension or model dimension can effectively minimize scaling.
Elements and Plugins#
The Deepstream SDK introduces Element as the fundamental functional block accessible through various plugins. Each type of element offers specific capabilities, including encoding, decoding, pre-processing, post-processing, AI inference, and Object Tracking. When integrated into a pipeline, an element initiates the processing of media buffers flowing through the pipeline, generating metadata or messages as a result.
Elements are highly configurable, supporting customization through key-value pairs or an external configuration file. This flexibility enables them to adapt to diverse task requirements. The output of an element, comprising data buffers, metadata, and messages, can be seamlessly captured by downstream counterparts for continuous processing. Alternatively, it can be retrieved by the application for external processing through customized objects.
An element can be instantiated using its predefined type name within the Deepstream SDK:
Element streammux("nvstreammux", "mux").set("batch-size", 1, "width", 1280, "height", 720);
A more practical approach supports instantiating and configuring an element through the higher-level Pipeline API:
pipeline.add("nvstreammux", "mux", "batch-size", 1, "width", 1280, "height", 720);
To properly direct the flow of media, elements need to be sequentially linked within the Pipeline. In most cases, a straightforward linking operation can be achieved using a simple link method, with the names of each Element instance specified in order. However, in certain scenarios, additional information may be required to facilitate the linking process. This complexity can arise from variations in how Elements handle inputs and outputs.
pipeline.add("nvurisrcbin", "src").add("nvvideoconvert", "converter");
// only the video output of the media source should be linked to the video converter
// "vsrc_%u" specify the video output of a nvuirsrcbin instance (refer to the plugin documentation)
pipeline.link({"src", "converter"}, {"vsrc_%u", ""});
Buffer#
The Buffer object serves as a wrapper for the data segments flowing through the pipeline.
For a read only buffer, you can invoke the read method to access the data in read-only mode, employing a customized callable object for data processing. Similarly, for a read-write buffer, the process is analogous, with the added capability of modifying the data within the buffer.
// example of a video buffer observer interface
class SampleBufferObserver : public BufferProbe::IBufferObserver {
public:
virtual probeReturn handleBuffer(BufferProbe& probe, const Buffer& buffer) {
// cast of a general buffer to a video buffer allows to thread the data in proper video format
VideoBuffer video_buffer = buffer;
video_buffer.read([byte](const void* data, size_t size) -> size_t {
const unsigned char* p_byte = (const unsigned char*) data;
for (auto p = p_byte; p < p_byte + size; p++) {
// take a peek on the data
}
return size;
});
}
};
Metadata#
In addition to the output data from an element, users may have a keen interest in the metadata generated by the element. This becomes particularly relevant in AI inference pipelines, where inference results are commonly conveyed in metadata format.
The following is a list of currently supported metadata objects:
Metadata class |
Description |
|---|---|
MetaData |
base class of all the metadata |
BatchMetaData |
metadata created through nvstreammux, acting as the root of all the other metadata and supporting iterating FrameMetaData and DisplayMetadata through the batch |
FrameMetaData |
metadata associated with a specific video frame, iterable within the BatchMetaData |
RoiMetadata |
metadata that describes a region of interest. |
UserMetaData |
user defined metadata |
ObjectMetadata |
metadata that describes a detected object, iterable with the FrameMetaData. |
ClassifierMetadata |
metadata that contains the classification information of an object, iterable within the ObjectMetadata or RoiMetaData. |
DisplayMetadata |
metadata that describes the display properties, being used by the nvdsosd to draw various shapes and text on a video frame, iterable with the FrameMetaData. |
EventMessageUserMetadata |
a specific type ofuser metadata for generating an event message, once appended to the FrameMetaData, it will be consumed by downstream message converter. |
PreprocessBatchUserMetadata |
a specific type of user metadata for describing the preprocess result of a batch of frames. |
TensorOutputUserMetadata |
a specific type of user metadata for describing the output tensor from a model, iterable within the FrameMetaData or RoiMetaData. |
SegmentationUserMetadata |
a specific type of user metadata for describing the segmentation result of a frame, iterable within the FrameMetaData or RoiMetaData. |
ObjectVisibilityUserMetadata |
a specific type of user metadata that contains a float value indicating the visibility of an object. |
ObjectImageFootLocationUserMetadata |
a specific type of user metadata that contains a pair of float values indicating the foot location of an object. |
TrackerPastFrameUserMetadata |
a specific type of user metadata carrying the past frame information of a tracker. |
More details about Deepstream Metadata can be found here.
SourceConfig#
SourceConfig is a convenience tool to load source configurations from a YAML file, allowing users append extra information to a source and create a list for multiple sources. A sample source config looks as follows
source-list:
- uri: "file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4"
sensor-id: UniqueSensorId1
sensor-name: UniqueSensorName1
- uri: "file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h265.mp4"
sensor-id: UniqueSensorId2
sensor-name: UniqueSensorName2
source-config:
source-bin: "nvmultiurisrcbin"
properties:
ip-address: "localhost"
port: 7000
batched-push-timeout: 33000
live-source: true
width: 1920
height: 1080
file-loop: true
max-batch-size: 16
There are 2 sections in the YAML file: source-list and source-config, each defines the inputs and the configurations of the source bin(s):
source-list: each item defines the uri, sensor-id and sensor-name for a source
source-config: defines the type of the source node and corresponding properties. The property specification under “properties” MUST be consistent with the type of the source node.
When the number of the streams fed into the pipeline is big and variable during runtime, separating the source config from the pipeline definition gives more clarity, however, it is always the developers’ decision for the most suitable approach.
CameraConfig#
CameraConfig is a convenience tool to load camera configurations from a YAML file, allowing users to create a list of multiple camera sources (V4L2/CSI). A sample camera config looks as follows:
camera-list:
- camera-type: "CSI"
camera-csi-sensor-id: 0
camera-width: 1280
camera-height: 720
camera-fps-n: 30
camera-fps-d: 1
- camera-type: "V4L2"
camera-v4l2-dev-node: 2
camera-width: 640
camera-height: 480
camera-fps-n: 30
camera-fps-d: 1
There is only one section in the YAML file: camera-list which defines the camera source and its configuration:
camera-list: each item defines camera-type, camera-width, camera-height, camera-fps-n, camera-fps-d, for CSI camera source: camera-csi-sensor-id and for V4L2 camera source: camera-v4l2-dev-node.
CommonFactory and custom Objects#
Application developers can utilize custom objects to access the processing results of specific Deepstream Elements tailored to their unique needs. These custom objects can be instantiated directly through the ‘new’ keyword if they are defined within the application code. Alternatively, if implemented through a plugin, they can be created through the common factory interface.
Custom objects can be incorporated into the pipeline using the ‘attach’ method, requiring the name of the element to which they should be attached.
Note
Upon attachment, the designated element will assume control of the lifecycle of the custom object.
The following is a list of currently supported custom objects:
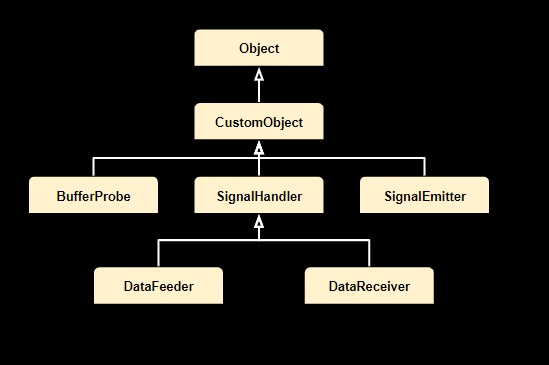
BufferProbe#
Application developers can employ a buffer probe to retrieve the output buffer generated within the pipeline. Various interfaces can be implemented based on the specific requirements of the probe, offering flexibility for different purposes.
Interface name |
Method |
description |
|---|---|---|
IBufferObserver |
handleBuffer |
access each processed buffer in read only mode |
IBufferOperator |
handleBuffer |
access each processed buffer in read write mode |
IBatchMetadataObserver |
handleMetadata |
access the batch metadata in read only mode |
IBatchMetadataOperator |
handleMetadata |
access the batch metadata in read write mode |
SignalHandler#
Signaling is a vital mechanism that facilitates interaction between elements within a running pipeline and the external world, notifying observers of specific events. An element can support a variety of signals, each uniquely registered during instantiation. The comprehensive details regarding signal support for an element can be found in the corresponding plugin manual.
Application developers have the flexibility to enhance the functionality of their applications by attaching signal handlers to Element instances. Once attached, these handlers respond promptly to the emitted signals, allowing developers to implement custom logic in response to specific events.
DataFeeder#
The DataFeeder signal handler is specifically designed for attachment to an Element instance to capture data request related signals, such as “need-data” and “enough-data” signals from an “appsrc.” By using DataFeeder, application developers gain the ability to seamlessly inject data directly into the target Element during runtime.
DataReceiver#
The DataReceiver signal handler is specifically for attachment to an Element instance to capture data ready related signals, such as “new-sample” signal from an “appsink.” By using DataFeeder, By using DataReceiver, application developers can receive the processed data from the target Element during runtime.
SignalEmitter#
The signal emitter is another pivotal component in the signaling mechanism, responsible for emitting signals rather than handling them. When an element seeks to have certain activities driven by the external environment, it accepts signal emitters. In this mechanism, with a signal emitter attached to an Element instance that is configured to receive such signals, corresponding activity will be triggered on the Element instance when the emit method is invoked on the signal emitter object.
Prepare and Activate#
For specific use cases, we have introduced alternative APIs to manage pipeline execution:
Pipeline.prepare()#
Unlike pipeline.start(), which transitions the pipeline’s state to playing in a new thread, pipeline.prepare() sets the pipeline’s state to paused within the same thread. This is particularly useful in multi-pipeline scenarios where each pipeline’s state needs to be changed to paused sequentially.
Pipeline.activate()#
After using pipeline.prepare(), pipeline.activate() transitions the pipeline’s state from paused to playing in a new thread. This effectively starts the pipeline. In multi-pipeline scenarios, this allows all pipelines to begin execution concurrently.
Pipeline.wait()#
This API is used to join the threads created by pipeline.activate(), ensuring that all threads complete their execution before proceeding.
The Sample Test 5 Application demonstrates how to utilize these API calls effectively.
State Transitions in Service Maker Pipelines#
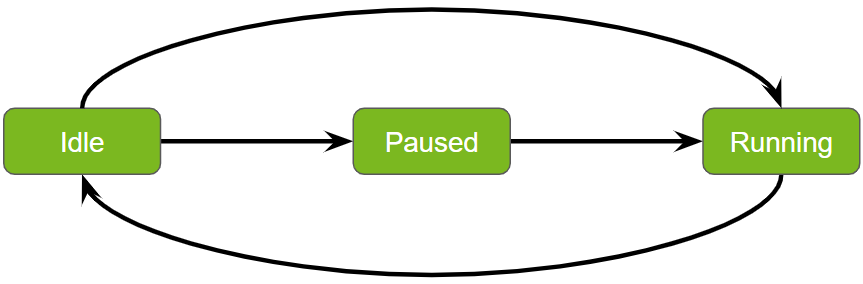
Managing state transitions in service pipelines is essential for ensuring efficient and orderly operations. Service maker facilitates synchronous state transitions, enabling smooth and predictable changes in the pipeline’s status. Here’s a clearer and more structured explanation of these transitions:
Start#
Transition: From idle to running.
Process: Utilize the pipeline.start() API to initiate the pipeline, moving it from an idle state to actively running tasks.
Prepare and Activate#
Transition: From idle to paused, then to running.
Process: By executing pipeline.prepare() followed by pipeline.activate(), the pipeline transitions through a paused state before becoming fully operational. This sequence allows for any necessary setup or configuration prior to execution.
Wait#
Purpose: Suspend the current thread until the pipeline completes its execution.
Process: The pipeline.wait() function is required after both the start and prepare/activate sequences to ensure that the current thread pauses until the pipeline has finished processing.
Stop#
Transition: Back to idle.
Process: The pipeline.stop() API is used to return the pipeline to its idle state, effectively halting operations and resetting it for future tasks.
These transitions are designed to manage workflow efficiently, allowing for both immediate execution and necessary preparatory phases.
Sample Applications#
Sample applications can be found from the Deepstream installation directory /opt/nvidia/deepstream/deepstream/service-maker/sources/apps/cpp/, and with the following commands user can build them:
$ cmake /opt/nvidia/deepstream/deepstream/service-maker/sources/apps/cpp/deepstream_test1_app && make
Migrating Traditional Deepstream Apps to Service Maker#
For users who have been integrating Deepstream applications into their solutions for an extended period, migrating to the new Service Maker APIs requires minimal effort.
Traditional Deepstream applications rely on configuration files for pipeline customization and parameter setup. The Service Maker APIs follow a similar approach, offering a configuration specification with slight differences:
Global Parameters
In the traditional Deepstream applications, all the global parameters need to be defined under a specific section named ‘applications’:
[application] enable-perf-measurement=1 perf-measurement-interval-sec=5 gie-kitti-output-dir=/tmp
With Service Maker APIs, some of the parameters are expected to be added as command line argument. For example, the test5 app built from the Service Maker can change the performance measurement interval through a command line argument:
—perf-measurement-interval-sec 5
As for others which are not truly ‘global’, they can be set as a property of the corresponding modules. For example, the ‘gie-kitti-output-dir’ is actually a property of the ‘kitti_dump_probe’ plugin built with the Service Maker, thus it can be set under the ‘Properties’ of the ‘kitti_dump_probe’ instance within the pipeline.
- type: kitti_dump_probe.kitti_dump_probe name: kitti_dump properties: kitti-dir: '/tmp'
Pipeline customization
In contrast to the traditional Deepstream application, Service Maker adopts a graph-based YAML definition to represent a pipeline structure, providing users with maximum flexibility for customization. The predefined sections in the traditional configuration, such as ‘primary-gie’, ‘secondary-gie’, ‘tracker’, ‘tiled-display’, and ‘osd’, can all be configured through the properties of each independent element within the Service Maker YAML definition.
Source and Batching
In traditional Deepstream applications, source management involves a combination of ‘sourceX’, ‘streammux’, ‘source-list’, and ‘source-attr-all’ in the configuration file. Service Maker simplifies this by separating the source management into a standalone source configuration file. In this file, source information, including ‘list’, ‘sensor-name-list’, and ‘sensor-id-list’, is placed within the ‘source-list’ section. Meanwhile, pipeline customization, such as specifying the source type and properties, is handled in the ‘source-config’ section.
Sink management
Compared to the traditional Deepstream application, Service Maker offers support for a wider range of arbitrary sink options. These include existing types such as ‘Fakesink’, ‘Display’, ‘File’, ‘UDP’, and ‘MsgConvBroker’. Each of these sinks must be defined within the graph pipeline specification, which includes all necessary element nodes and the edges between them. This approach provides greater flexibility in configuring sinks for the pipeline.
Smart Recording Feature
Test5 application can be configured to record the original video feed based on the event received from the server. In this way, instead of saving data all the time, this feature allows to record only event of interests. Refer to the DeepStream plugin manual and
gst-nvdssr.h ``header file for more details about smart record. Event based recording can be enabled by setting ``smart-recordunder[sourceX]group. Currently test5 app only supports source type = 4 (RTSP). Similar approach can be used for other types of sources as well. There are two ways in which smart record events can be triggered:ServiceMaker-test5 application can be configured to record video feed based on the event received from server. This is available for nvurisrcbin module only.
To use Smart Record feature set properties example:
source-config: source-bin: "nvurisrcbin" properties: smart-record: 1 # 1 for cloud messages, 2 for local events smart-rec-dir-path: /tmp/record smart-rec-container: 0 # Default 0 for mp4, 1 for mkv
Following minimum Json message is expected to trigger the start / stop of smart record on topic test5-sr:
{ command: string // <start-recording / stop-recording> start: string // "2022-01-07T20:02:00.051Z" end: string // "2022-01-07T20:02:02.851Z", sensor: { id: string } }NOTE: Before running the app must run ‘mkdir /tmp/record’ to create the directory with writing permission.