Gst-nvinferaudio#
The Gst-nvinferaudio plugin does inferencing on input data using NVIDIA® TensorRT™.
The plugin accepts batched audio buffers from upstream. The NvDsBatchMeta structure must already be attached to the Gst Buffers.
The low-level library (libnvds_infer) operates on transformed audio data with dimension CHW.
The Gst-nvinferaudio plugin performs transform (log mel spectogram), on the input frame based on audio-transform property setting and transformed audio data is passed to the TensorRT engine for inferencing.
The output type generated by the low-level library depends on the network type.
Gst-nvinferaudio currently works on the following type of networks:
Encoder Decoder RNN Architecture
CNN
Detailed documentation of the TensorRT interface is available at: https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html
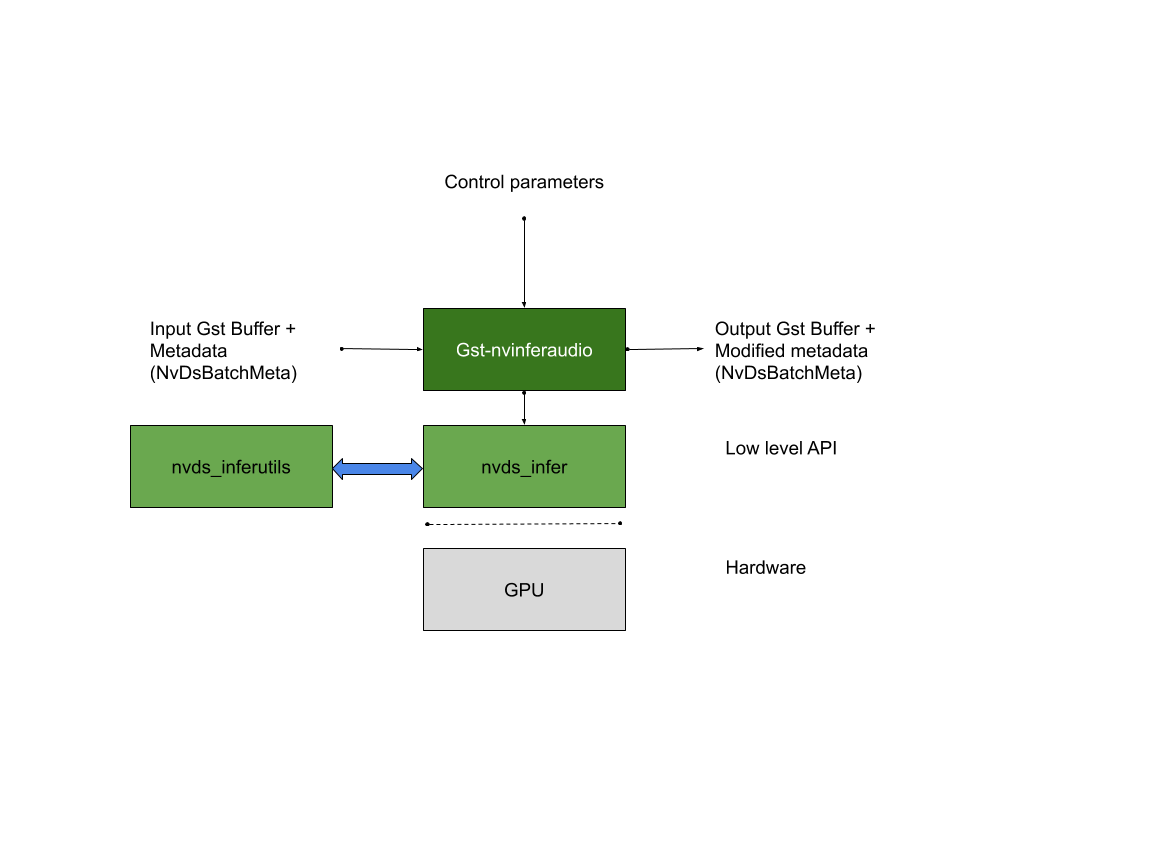
Downstream components receive a Gst Buffer with unmodified contents plus the metadata created from the inference output of the Gst-nvinferaudio plugin.
Inputs and Outputs#
This section summarizes the inputs, outputs, and communication facilities of the Gst-nvinferaudio plugin.
Inputs
Gst Buffer
NvDsBatchMeta (attaching NvDsFrameMeta)
ONNX
Layers: Supports all layers supported by TensorRT, see: https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html
Control parameters
Gst-nvinferaudio gets control parameters from a configuration file. You can specify this by setting the property config-file-path. For details, see Gst-nvinferaudio File Configuration Specifications. Other control parameters that can be set through GObject properties are:
Batch size
Inference interval
Attach inference tensor outputs as buffer metadata
Attach instance mask output as in object metadata
The parameters set through the GObject properties override the parameters in the Gst-nvinferaudio configuration file.
Outputs
Gst Buffer
NvDsFrameMeta
NvDsClassifierMeta
Features#
The following table summarizes the features of the plugin.
Gst-nvinferaudio plugin features# Feature
Description
Release
nvinferaudio plugin for audio inference
Introducing nvinferaudio
DeepStream 5.1.0
The Gst-nvinferaudio configuration file uses a “Key File” format described in https://specifications.freedesktop.org/desktop-entry-spec/latest. The [property] group configures the general behavior of the plugin. It is the only mandatory group. The [class-attrs-all] group configures detection parameters for all classes. The [class-attrs-<class-id>] group configures detection parameters for a class specified by <class-id>. For example, the [class-attrs-23] group configures detection parameters for class ID 23. This type of group has the same keys as [class-attrs-all]. The following two tables respectively describe the keys supported for [property] groups and [class-attrs-…] groups.
Gst-nvinferaudio Property Group Supported Keys# Property
Meaning
Type and Range
Example Notes
num-detected-classes
Number of classes detected by the network
Integer, >0
num-detected-classes=91
Detector Both
net-scale-factor
Pixel normalization factor
Float, >0.0
net-scale-factor=0.031
All Both
model-file
Pathname of the caffemodel file. Not required if model-engine-file is used
String
model-file=/home/ubuntu/model.caffemodel
All Both
proto-file
Pathname of the prototxt file. Not required if model-engine-file is used
String
proto-file=/home/ubuntu/model.prototxt
All Both
int8-calib-file
Pathname of the INT8 calibration file for dynamic range adjustment with an FP32 model
String
int8-calib-file=/home/ubuntu/int8_calib
All Both
batch-size
Number of frames or objects to be inferred together in a batch
Integer, >0
batch-size=30
All Both
model-engine-file
Pathname of the serialized model engine file
String
model-engine-file=/home/ubuntu/model.engine
All Both
onnx-file
Pathname of the ONNX model file
String
onnx-file=/home/ubuntu/model.onnx
All Both
labelfile-path
Pathname of a text file containing the labels for the model
String
labelfile-path=/home/ubuntu/model_labels.txt
Detector & classifier Both
output-blob-names
Array of output layer names
Semicolon delimited string array
For detector: output-blob-names=coverage;bbox
For multi-label classifiers: output-blob-names = coverage_attrib1;coverage_attrib2
All Both
custom-lib-path
Absolute pathname of a library containing custom method implementations for custom models
String
custom-lib-path=/home/ubuntu/libresnet_custom_impl.so
All Both
classifier-threshold
Minimum threshold label probability. The GIE outputs the label having the highest probability if it is greater than this threshold
Float, ≥0
classifier-threshold=0.4
Classifier Both
output-tensor-meta
Gst-nvinfer attaches raw tensor output as Gst Buffer metadata.
Boolean
output-tensor-meta=1
All Both
network-type
Type of network
Integer 0: Detector 1: Classifier 2: Segmentation 3: Instance Segmentation
network-type=1
All Both
parse-classifier-func-name
Name of the custom classifier output parsing function. If not specified, Gst-nvinfer uses the internal parsing function for softmax layers.
String
parse-classifier-func-name=parse_bbox_softmax
Classifier Both
custom-network-config
Pathname of the configuration file for custom networks available in the custom interface for creating CUDA engines.
String
custom-network-config=/home/ubuntu/network.config
All Both
workspace-size
Workspace size to be used by the engine, in MB
Integer, >0
workspace-size=45
All Both
force-implicit-batch-dim
When a network supports both implicit batch dimension and full dimension, force the implicit batch dimension mode.
Boolean
force-implicit-batch-dim=1
All Both
infer-dims
Binding dimensions to set on the image input layer.
channel;
infer-dims=3;224;224
All Both
uff-input-order
UFF input layer order
Integer 0: NCHW 1: NHWC 2: NC
uff-input-order=1
All Both
engine-create-func-name
Name of the custom TensorRT CudaEngine creation function. Refer to the “Custom Model Implementation Interface” section for details
String
engine-create-func-name=NvDsInferYoloCudaEngineGet
All Both
output-io-formats
Specifies the data type and order for bound output layers. For layers not specified, defaults to FP32 and CHW
Semi-colon separated list of format. <output-layer1-name>:<data-type>:<order>;<output-layer2-name>:<data-type>:<order>
data-type should be one of [fp32, fp16, int32, int8]
order should be one of [chw, chw2, chw4, hwc8, chw16, chw32]
output-io-formats=conv2d_bbox:fp32:chw;conv2d_cov/Sigmoid:fp32:chw
All Both
Layer-device-precision
Specifies the device type and precision for any layer in the network
Semi-colon separated list of format. <layer1-name>:<precision>:<device-type>;<layer2-name>:<precision>:<device-type>;
precision should be one of [fp32, fp16, int8]
Device-type should be one of [gpu, dla]
layer-device-precision= output_cov/Sigmoid:fp32:gpu;output_bbox/BiasAdd:fp32:gpu;
All Both
Gst-nvinferaudio Class-attributes Group Supported Keys# Name
Description
Type and Range
Example Notes
(Primary/Secondary)
threshold
Detection threshold
Float, ≥0
threshold=0.5
Object detector Both
Gst Properties#
The values set through Gst properties override the values of properties in the configuration file. The application does this for certain properties that it needs to set programmatically. The following table describes the Gst-nvinferaudio plugin’s Gst properties.
Property |
Meaning |
Type and Range |
Example notes |
|---|---|---|---|
config-file-path |
Absolute pathname of configuration file for the Gst-nvinfer element |
String |
config-file-path=config_infer_primary.txt |
unique-id |
Unique ID identifying metadata generated by this GIE |
Integer, | 0 to 4,294,967,295 |
unique-id=1 |
infer-on-gie-id |
See operate-on-gie-id in the configuration file table |
Integer, 0 to 4,294,967,295 |
infer-on-gie-id=1 |
operate-on-class-ids |
See operate-on-class-ids in the configuration file table |
An array of colon- separated integers (class-ids) |
operate-on-class-ids=1:2:4 |
filter-out-class-ids |
See filter-out-class-ids in the configuration file table |
Semicolon delimited integer array |
filter-out-class-ids=1;2 |
model-engine-file |
Absolute pathname of the pre-generated serialized engine file for the mode |
String |
model-engine-file=model_b1_fp32.engine |
batch-size |
Number of audio frames to be inferred together in a batch |
Integer, 1 – 4,294,967,295 |
batch-size=4 |
Interval |
Number of consecutive batches to be skipped for inference |
Integer, 0 to 32 |
interval=0 |
gpu-id |
Device ID of GPU to use for pre-processing/inference (dGPU only) |
Integer, 0-4,294,967,295 |
gpu-id=1 |
raw-output-file-write |
Pathname of raw inference output file |
Boolean |
raw-output-file-write=1 |
raw-output-generated-callback |
Pointer to the raw output generated callback function |
Pointer |
Cannot be set through gst-launch |
raw-output-generated-userdata |
Pointer to user data to be supplied with raw-output-generated-callback |
Pointer |
Cannot be set through gst-launch |
output-tensor-meta |
Indicates whether to attach tensor outputs as meta on GstBuffer. |
Boolean |
output-tensor-meta=0 |
output-instance-mask |
Gst-nvinfer attaches instance mask output in object metadata. |
Boolean |
output-instance-mask=1 |
audio-transform |
Transform name and parameters |
Boxed pointer of type “GstStructure” |
audio-transform= melsdb,fft_length=2560,hop_size=692,dsp_window=hann, num_mels=128,sample_rate=44100,p2db_ref=(float)1.0, p2db_min_power=(float)0.0,p2db_top_db=(float)80.0 |
audio-framesize |
Frame size to use for transform |
Unsigned Integer. Range: 0 - 4294967295 |
audio-framesize=441000 |
audio-hopsize |
Hop size to use for transform |
Unsigned Integer. Range: 0 - 4294967295 |
audio-hopsize=110250 |
Audio Transform parameters |
Description |
|---|---|
audio-transform |
Options: melsdb |
fft_length |
FFT length (unsigned int) |
hop_size |
Hop size (unsigned int) |
num_frequencies |
Number of frequency bins for specified FFT length (unsigned int) |
dsp_window |
DSP Window type (char*) Options: none hann hamming |
num_mels |
Number of mel bins (unsigned int) |
sample_rate |
Sample rate (unsigned int) |
p2db_ref |
DSP parameters for power_to_db Reference (float) |
p2db_min_power |
DSP parameters for power_to_db Min power (float) |
p2db_top_db |
DSP parameters for power_to_db Top DB (float) |
attach-sys-ts |
Support pending and shall be added with future releases. |